
引言
很多组织谈论 AI 时,仍然把重点放在模型质量上,仿佛这就是决定成败的关键。但在企业环境里,真正的限制往往并不在这里。
更重要的问题其实是:模型拿到了什么上下文,它又以什么权限访问企业知识?
为什么上下文比想象中更重要?
同一个模型,如果它:
- 能看到内部制度,
- 能访问相关的客户或项目数据,
- 理解企业自己的术语,
- 并且只能使用被授权的来源,
它给出的结果就会完全不同。
所以,企业级 AI 的价值,很大程度上其实是一个上下文工程问题。
三个基础层
1. 数据
AI 到底从哪些来源工作?是文档、工单、CRM、ERP、知识库,还是邮件摘要?
2. 上下文
这些数据经过了怎样的筛选、排序、优先级处理和解释性包装?
3. 权限
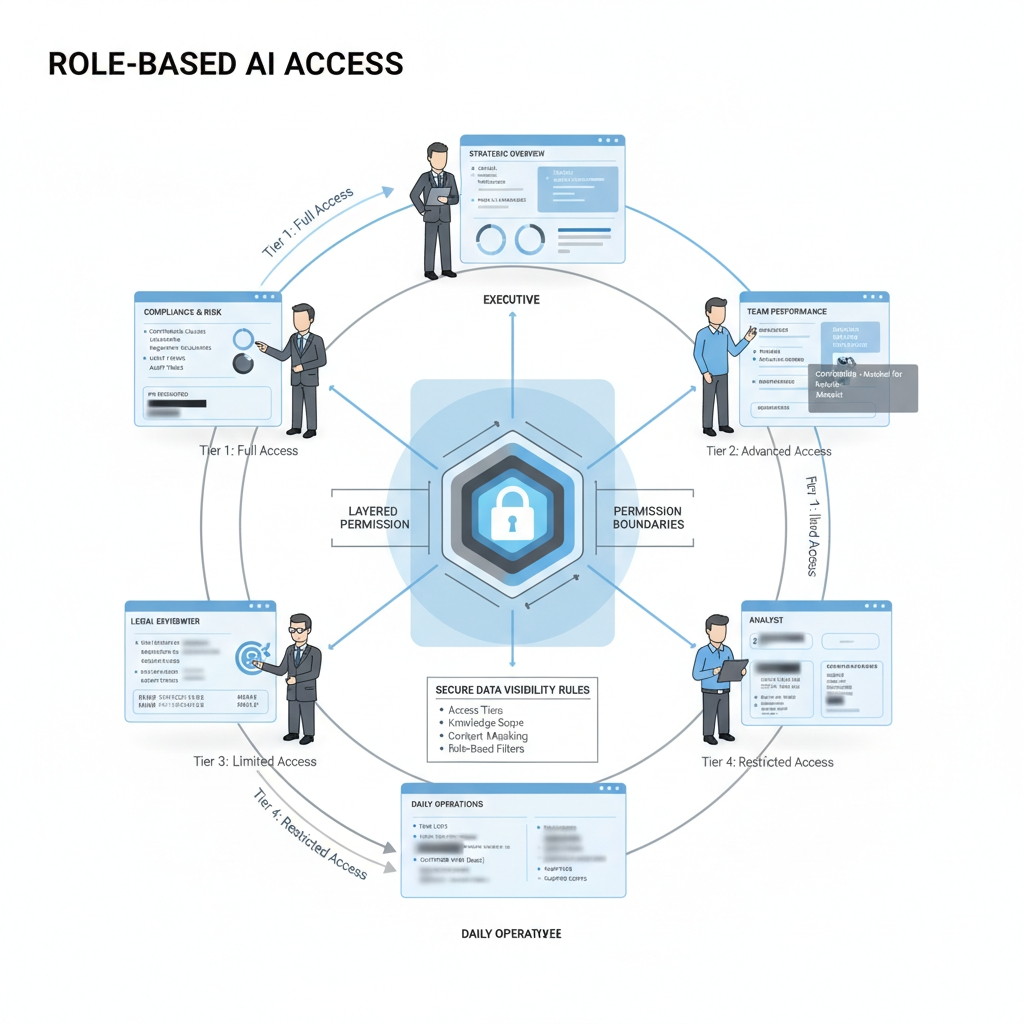
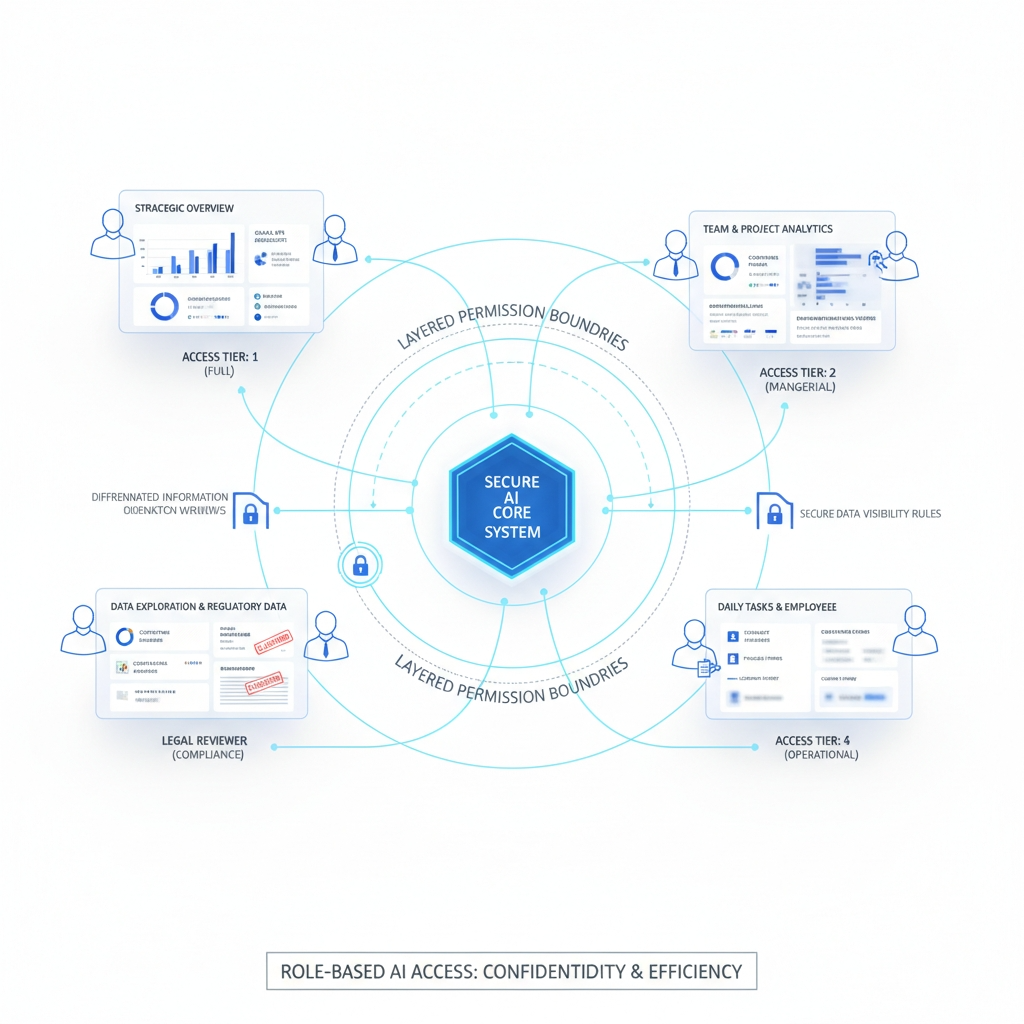
它能看什么,不能看什么,以什么角色看,以及有没有日志可追踪?
如果这三层没有一起设计好,那么即使模型本身很强,业务上的使用效果依然会很弱。
企业里常见的问题
知识分散
知识散落在多个系统里,而且质量并不一致。
文档空间嘈杂
存在大量过时、重复甚至彼此矛盾的文档。
权限模式不合理
AI 不是看得太多,就是看得太少。
缺少可审计性
人们看不出输出到底基于哪些来源生成。
应该先整理什么?
划定首批来源范围
不要一开始就把所有系统都接进来。第一个 use case 需要的是一个被挑选过、可以信任的来源集合。
做好文档卫生
旧文档、误导性文档和无人维护的文档都会带来很大风险。
建立基于角色的访问
同一个问题,在管理层、运营层和客服岗位上的含义并不一样。
建立可追踪性
必须能够回溯,一条回答或建议究竟是由哪些来源构成的。
architect 的角色在哪里体现?
这里尤其关键。
architect 的职责可能包括:
- 设计来源系统接入策略,
- 协调权限模型,
- 建立可复用的上下文构建模式,
- 以及规划审计能力。
很多组织正是在这里意识到,AI 计划其实也是推动数据架构升级的催化剂。
结语
企业级 AI 并不只是“提问与回答”。它更像是一种对相关企业知识的受治理访问。 所以在 AI 时代,仅仅选一个好模型还不够。还必须围绕它建立好的上下文和好的权限模型。


